
Chapter 1 はじめに
ソフトウェア開発における限界は、自分たちが作ろうとしているシステムを自分たちがどれくらい把握出来ていることに依存している。
つまり、もしちゃんと頭で描けているなら、システムはもう出来たも同然。
でも、プログラムの複雑性は必ず増える。時と共に。
ソフトウェアをシンプルに保ち続けることを目指しなさい。その方が安定した巨大なシステムを作れる。
複雑性と戦うための一般的な2つのアプローチ
- シンプルなコードを書いて複雑さを除去する
- 複雑さを隠蔽する
modular designと原著で書いてある。モジュール化?
Softwareは日々成長し、完成という状態は存在しない。常に状態は連続的。
-> 著者はここでWaterfallをややディスる。
ようするに、インクリメンタルな開発手法のほうが、そもそもソフトウェアという曖昧な性質をもつ製品には向いていると。
-> lean, agile
この本は、SDをそのソフトウェアの寿命が来るまできちんと考えていくためのヒント
この本の使い方。
この本に書いてあることは、それなりに抽象的。
だから具象コードのサンプルを見ないと評価しづらい。
本書の一番いい使い方はコードレビューと共に使うこと!
この本はコードの危険な匂いをどのように判別するかを紹介する。本文ではred flagと書かれていた。直訳すると赤旗。これは和訳NG
※Refactoring(Martin Fawler)よりも抽象的なコード改善の指針本と見てよいのでは?
ただし、デザイン指針の適用には常に節度と方向性をもつべし。
過剰適用は禁物、エクストリームにやるとだいたい悪いことになる。
いくつかの章には過剰適用についての項目を設けてあるので嫁。
この本を読んで、何が複雑さを作り出すのかを理解して、シンプルなシステムの作り方を学ぶのです。
サンプルコードはJavaか、C++
全21章。最後の章は結論。
Chapter 2 複雑性の本質
複雑性の本質
この章は、この全体の前提知識。この章をベースにして今後の議論が行われる。
複雑性を最小化するには、まず敵を知る必要がある。
複雑性とは何か?
この章において、高次の抽象化された表現として複雑性について説明する。
低次の具体的な複雑性の対処は3章以降で扱う。
複雑性を認識する能力こそが、Software Designにおける決定的な能力。
-> 訓練するうちに、特定のやり方がシンプルなデザインに帰結しがちという傾向に気付けるようになる。
複雑性を定義する
複雑性とは
「ソフトウェアシステムの理解を難しくしたり変更を困難なものにする、ソフトウェアシステムの構造に関わる全て」
例
もし、ソフトウェアが理解しづらくて、変更も辛い場合、そのソフトウェアは複雑(complicated)。
逆に、ソフトウェアが理解しやすくて、変更も容易な場合、そのソフトウェアはシンプル。
ただし、例え色んなモジュールが複雑(Complex)で巨大なソフトウェアだったとしても、理解や変更が容易な場合は、そのソフトウェアはシンプル。
訳注) Complexity(複雑性)とComplicated(とっちらかってる)が使い分けられています。Complexはソフトウェア自体は入り組んでるけど、問題ない状態をさしていて、Complicatedは駄目な複雑性を示している。
C=ΣCpTp
これは、複雑性を表す式
Cpはシステムのそれぞれのパートにおける複雑性
Tpはシステムのそれぞれのパートの理解にかかる時間
これを乗算した上で、全てのパートの積算したものが、全体の複雑性C
つまり、複雑でも理解が容易であれば、全体の複雑性に与える影響は少なくなる。
複雑性は、公的な認識である必要がある。
- 自分は分かるけど、他の人にはわからないのは複雑性が高い。
- 他の人も理解できるコードを書くことこそが開発者としての責務。
複雑性の症状
大きく分けて3つの複雑性の症状がある。
Change Amplification
変更の倍々ゲーム
例えば、HTMLで各ページのBodyタグにインラインでbackground-colorが設定されている場合。
背景色の変更は、各ページのBodyタグを書き換える必要があるので、x nページの複雑性を持つ。
Cognitive load
認知の重荷
例えば、C言語のプログラムで、とあるモジュールがメモリーを割り当てするが、モジュール側で開放しない場合。
利用者はそのモジュールを利用したときに、メモリーを開放しないといけない。
この知識が事前に開発者にLoadされていないといけない。これが認知の重荷。
とあるシステムに変更を加えるときに、事前に必要となる知識の量。
プログラミングにおいて、行数が少ないことを美点とすることが多いが、行数が多くても認知負荷が低いのであれば、行数が多いほうがシンプルでよい場合もある。
Unknown unknowns
無自覚の無自覚
3つの複雑性の中でも最悪なものがコレ
システムの開発において、あなたが知らなければならない何かがあるが、それが何であるかを知るすべがない。
もしくは、何かを知らなければならないという課題すらが分かっていない。
最終的にリリースして、不具合としてエスカレーションされるまで、問題に気づくことも出来ない。
複雑性の原因
dependencies and obscurity
依存と曖昧
例えば、メソッドのシグネチャー(引数や戻り値の型)は依存を作り出す。メソッドの利用者は特定のシグネチャーで実装をしている。
依存が存在している場合、シグネチャーの変更は全ての依存先に対する変更を行う必要性を示唆している。
Dependencies 依存
完全になくすことはできない。プログラマーは意図的に依存性を作り出したりもする。そしてそれはデザインプロセスの一部だったりもする。
しかし、依存を取り扱う一つのゴールは、依存を少なく保ち、その依存関係をシンプルで明確なものに保つこと。
Webサイトの例でいえば、全てのページの背景色をbannerBGという名前でCSSに切り出したとすれば、これは依存関係を一つにした上で、その利用箇所をbannerBGという名前で検索できるので、シンプルに保たれている。これは良い依存。
APIなどでいえば、Interfaceを定義することで、プログラムの実行前に依存先の実装エラーを検知できる仕組みも明確で良い依存。
Obscurity 曖昧
重要な情報が適切に明確化されていないときに発生する。
例えば、変数名がtimeという名前だとすると、この名前は複雑性を作り出している。timeは何を表す時間なのか??
変数に数値が入るとして、その単位がDocumentにかかれていない場合、それも複雑性を作り出す。グラム?ポンド?
エンジニアは、コードからそれを知ることは出来ない。
曖昧は、不適切な文書化から入り込んでくることが多い。詳細は13章で扱う。
曖昧の軽減も、シンプルなソフトウェアデザインで達成することが出来る。
それぞれが導く複雑性
Dependencies(依存)は、変更の倍々ゲームや認知の負荷へつながる。
Obscurity (曖昧)は、無自覚の無自覚と認知の負荷へつながる。
複雑さは積み上がる。
時と共に複雑性は積み上がる。あなたが今行っている変更が作り出す複雑性は、大したことがないと思うかもしれない。
でも、複雑性は積算です。みんなが、大したことないと思って積み上げた複雑性が、最終的にシステム全体の複雑さにつながります。
結論
複雑性は、依存と曖昧の積み上げより発生する。そして複雑性はコード修正を難しくて、システムを理解させることを妨げる。
複雑性こそが、我々の敵。
Chapter 3 動くだけのコードは不十分
動いているコードだけでは十分ではない。
strategic vs tactical Programing
戦略的プログラミングと戦術的プログラミング
戦術的プログラミング
殆どのプログラマーはソフトウェア開発を戦術的プログラミング(彼がそう名付けた)で行っている。
訳注 Tactical ProgrammingはGTD(Getting Things Done)タイプのプログラミングのこと
しかしながら、戦術的プログラミングでは良いシステムデザインはほぼ不可能。
戦術的プログラミングの問題点
視野が狭い -> タスクを以下に早く終わらせるかに焦点が当たっている -> 未来のための設計は優先度が低い
あなたは、ほんの少しの良くないコードが足されることは、別に構わないと考える。ほんの少しの複雑性の追加は問題ない。
-> それよりも、現在のタスクを少しでも早く終わらせたほうがよいと考える。
そして、これこそがシステムが複雑にする方法です。
前章で学んだ通り、複雑性は一つの良くないコードによってもたらされるのではなく、細かい良くないコードの積み重ねが原因です。
プロジェクトに参加する全員がタスクを早く終わらせることに焦点をあてて作業すると、複雑性がどんどん積算されていきます。
この先に待ち受けている展開
- 複雑性が少しずつ積まれていき、前回タスクで急ぎすぎたことを少し悔いる
- でも、少しでも早くタスクを終わらせられたから良かったのだと自分を納得させる
- リファクタリングしたら、状況は改善すると頭に思い浮かべる。
- でも、今のタスクも少しでも早く終わらせたいから、後回しにする。
-> この繰り返しを経て、コードは取り返しのつかないほどに複雑になる(mess)
この段階に至ると、コードの複雑性を排除するためにかかる労力は膨大になっており、プロダクトにその遅れを適用することは政治的に不可能になっている。
一度、技術集団が戦術的な方向性を取り始めると、方向性の修正はどんどんむずかしくなる。
戦術的トルネード
どの組織にも、タスクを高速で処理する戦術的プログラミングの化身のような人がいる。
彼らはマネージャーからはヒーローとして扱われることもあるが、激しい複雑性を背後に残すことになる。
そして、その複雑性を少しずつ解きほぐして前進する本当のヒーローは、ゆっくりとした進捗を出すため、組織内で低く評価される可能性さえある。
戦略的プログラミング
良いソフトウェアデザイナーになる最初の一歩は、ただ動くコードは十分ではないということを認識することから始まる。
戦略的プログラミングとは
最優先のゴールとして、素晴らしいデザインを作り出すことである。
そして、その素晴らしいデザインのコードが、たまたまタスクで求められた機能を充足している。
戦略的プログラミングに必要なマインドセットは投資の感覚。
最速の道をいくのではなく、将来を考えた道のりを進む。
投資の視点
Proactive (積極的
作り出そうとしているコードの最初の設計で作り出すのではなく、よりよい方法が無いかを考える。
どのような将来が待ち受けているかを想像して、その将来に対して変更容易なデザインを考える。
良いドキュメントを作成して残すことも、積極的投資の例
Reactive (受動的
どんなに良く考えたとしても、世の中は予測不能で複雑です。あなたのデザインは何がしかの欠陥や欠点を持つ。
その欠点が発見されたときに、それを無視したり、強引に乗り切るのではなく、より良いデザインを考える時間をとる。
どのくらい投資すれば良いのか?
全てを事前に緻密に設計するとかはどう?
-> これはWaterfallの考え方。そして、これは効果的でないことを私達は知っている。
より良いデザインは、コードを作り続ける過程で、プログラマーが少しずつ知見をためていく過程で、生まれてくる。
おすすめは、小さい投資(10~20%)を継続的にコーディングの過程で行っていくこと。
いきなりいっぱい投資するのではなく、継続的に常に投資し続けるのが大事。
小さい投資を実施し続けて、将来の複雑性が排除されていけば、この程度の投資はすぐに回収できる。開発時間は、全体を通じて低く抑えられる。
戦略的プログラミングは、最初のうちは戦術的プログラミングより遅い進捗を見せるが、すぐにブッちぎることができる。
スタートアップと投資
アーリーステージのスタートアップは、10~20%の投資さえ渋る。
戦術的トルネードを採用して、とにかく動くコードを最速で作らせるというアプローチを取る。
例え、ひどいコードベースでスタートアップが多少の成功を収めたとしても、ひどいコードベースは採用にも影響を与える。
Facebookはその最たる例で、当初のスローガン 「Move fast and break things」
に則って、GTDでクソコードを量産した結果、複雑性が拡大して、事業の成長がおぼつかなくなってしまった。
彼らはスローガンを変更して「Move fast with solid infrastructure」になった。そして、エンジニアにより良いデザインを行うことを推奨するようになった。
逆に戦略的アプローチで成功したのは、VMWareとかGoogle。
シリコンバレーの歴史は、いずれのアプローチでも成功できることを示しているが、より働いていて楽しいのは、戦略的アプローチを取っている会社であることは自明。
まとめ
よいソフトウェアデザインは、タダじゃない。
大事なことは、負債を一挙に返済しようとするのではなく、継続的に小さい投資を続けること。
複雑性への対処を遅らせれば遅らせるほど、状況はどんどん悪化する。放置してはならない。
エンジニア全員が小さい改善を積み重ねていく態度を見せることが、もっとも効果的なアプローチである。
Chapter 4 モジュールは深くあるべき
ソフトウェアの複雑性を制御する最も重要なテクニックは、開発者が様々な状況において、限定的で小さな複雑性のみ対処すれば良いようにデザインすること。
このアプローチを modular design モジュラーデザインと呼ぶ。
日本語訳にブロック工法とか出てくるけど、とりあえずモジュラーデザインでいきます。
モジュラーデザイン
ソフトウェアをモジュールの集合としてデザインする。各モジュール間は比較的独立している。
モジュールは、いかなる形でも構わない。classでもサブシステムでも、他サービスでもいい。
理想的な世界では、全てのモジュールが完全に独立している。実世界において、システムの複雑性は、システムを構成する最も複雑で分かりにくいモジュールの複雑性に依存する。
不幸にも、完全に独立したモジュールはありえない。モジュールは他のモジュールを呼び出す必要がある。そして呼び出す以上は依存関係が発生する。もし、片方のモジュールが修正されたら、もう一方のモジュールも修正される必要が出てくる可能性がある。
依存性は、様々な形状を取る、そして非常にわかりにくくかすかな依存性もある。とっても厄介。
モジュラーデザインのゴールは、この依存性を極力小さくすること。
依存性を制御するために、私達はモジュールを2つのパーツに分けて考える。それは
- インターフェース
- 実装
ここで歓声があがる
インターフェース
このモジュールが何をするのかを表すのがインターフェース。どのようにやるのか?は利用者は知らなくていい。
開発者は、インターフェース以上の情報を知るべきではない。
二分木の実装を考えてみよう。ノードにエレメントを追加するインタフェースが用意されてれば利用者は問題ない。実装の詳細はモジュールの開発者が頑張ればいい。
この本の目的として、モジュールとはインターフェースと実装を持つ一連のコードのことを表します。OOPのクラスなんかはまさにモジュールです。OOP以外におけるTop-levelの関数群なんかもいちおうモジュールと呼ぶ。上位層のサブシステムやサービスなんかもモジュールと言える。インターフェースはHTTPリクエストのAPI仕様書かもしれないけど。
ただし、この本が主に焦点を当てるのは、クラスの設計。でもコンセプトとかテクニックは、他の形状のモジュールにも適用できるはず。
ベストなモジュールとは、シンプルなインターフェースでかつ、複雑な実装をこなしてくれるものです。
このようなモジュールは2つの利点をもちます。
- シンプルなインタフェースは、これを利用する他のモジュールの複雑性を下げる
- インタフェースを変更しない限り、これを利用する他のモジュールには影響が出ない。
インターフェースとは何か?
インタフェースは、公式と非公式の情報をもつ。
公式情報は、ソースコードとして外部にもわかるように表現される。メソッドやその引数は公式情報。
非公式情報とは、プログラミング言語自体が察知できないような情報、例えばメソッドには呼び出し順があるとか、特定の引数を与えると通常と異なる動作をするとか、これらはコメントにしか書く場所がない。
非公式情報が増えれば増えるほど、インターフェースは複雑になる。
非公式情報は、前述の わからないことがわからない に相当する。モジュールの非公式情報を読まないとちゃんと扱えないモジュールというのは、よい状態ではない。
抽象化
抽象化は、モジュラーデザインの考えに深く関連する。抽象化というのは、簡潔に実体を示すこと、重要でない詳細を削ぎ落とすこと。
モジュラープログラミングでは、インタフェースという形式で抽象化された実体を表現する。
抽象化の定義に置いて、重要でないという言葉は鍵になる。
重要でないものをどんどん削ぎ落としていくことで、よい抽象化が行える。
しかし、重要でない ときに限って、その情報は削ぎ落としてよい。抽象化は2つの方法でおかしなことになる可能性がある。
1番目
重要でない詳細をインターフェースに含んでしまう場合
2番目
重要な詳細を削ぎ落としてしまった場合、これは曖昧さにつながる。これは間違った抽象化
これをやると、利用者がソースコードを見に行かないと分からないというインタフェースになる。
重要な情報のみをいかに残していくかが鍵
抽象化の例
ファイルシステムは、良い抽象化の例。Finderでファイルを削除したりコピーしたり。特に実装の詳細を知らなくてもユーザはファイルシステムを利用できる。
考えてみれば、我々は抽象化されたインタフェースを常に使っている。車の運転、電子レンジ、電気モーターなどなど
Deep Module 深いモジュール
前述の通り、良いモジュールはシンプルなインタフェースで、強力な機能を提供する。
私はこれを 深いモジュール と呼ぶ。
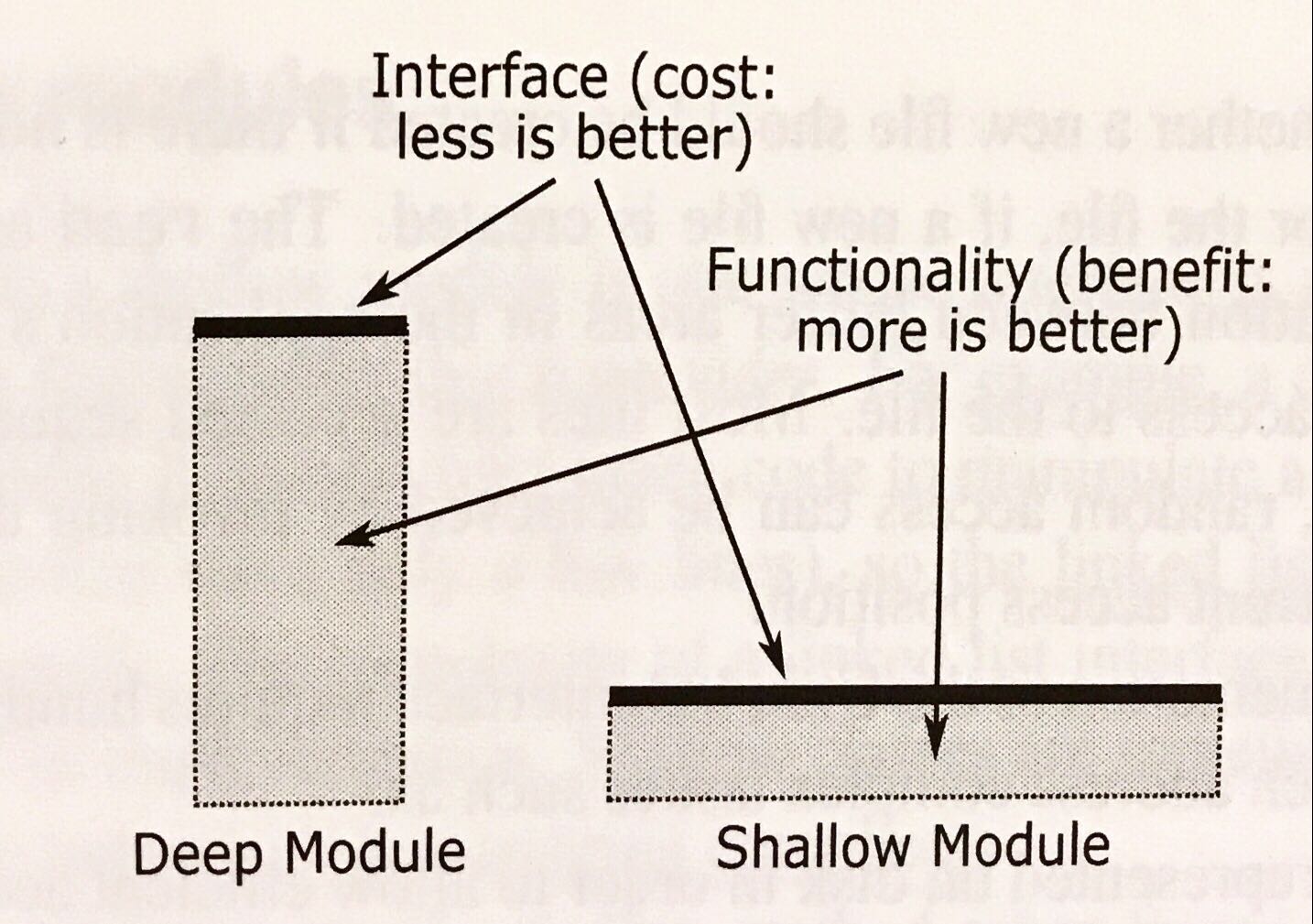
図の左側、深いモジュールはシンプルなインターフェースで、たくさんの機能を提供する。
逆に浅いモジュールは、インタフェースが曖昧で機能の提供も少ない。
モジュール設計は、コストと利益の感覚で捉えると良い、利用者視点に立つならば、インターフェースこそがコスト。シンプルなインタフェースはコストが少なくなる。
UnixのFile I/Oを例にとる。インターフェースは5つだけ(システムコール)
- int open
- ssize_t read
- ssize_t write
- off_t lseek
- int close
この実装は、とんでもなく複雑だけど、ユーザは意識する必要がない。これは素晴らしい例。
プログラミング言語のGC機構も深いモジュールの例
GCに至ってはバックグランドで動作するので、インタフェースは無。しかし、プログラミングから複雑性を大幅に減らすことができる。
Shallow modules 浅いモジュール
深いモジュールの反対。インターフェースが複雑なのに大した機能を提供しない。
LinkedListの実装なんかは、浅いモジュールの代表例
private void addNullValueForAttribute(String attribute) {
data.put(attribute, null);
}
この関数は、複雑性を何一つ減らしていない。浅いモジュールの典型例。このモジュールはコード量を増やしているだけで、何も状況を改善しない。コードが増えている分、複雑性が増えている。
時に浅いモジュールが必要になることも理解は出来るが、小さいモジュールは浅いモジュールになりやすい。
クラス症候群
クラスは小さくあるべきという伝統的な態度によって、クラス症候群が発生する。クラスをどんどん分割して、小さく小さく分けていく。CSの授業でもこういう教えが蔓延しているので、生徒の大半はクラスを驚くほど小さく分ける。
N行以上のメソッドは撲滅すべきという教義もいまだにプログラミング業界では根強い。これを真面目に取り入れると、細切れになりすぎたメソッド群が誕生する。
クラス症候群は、小さくてシンプルなクラスを手に入れるが、全体的に複雑で制御しにくいプログラムを生み出す。
これらは、シンプルなプログラムではなく冗長なプログラムを生み出す。それぞれの小さく分割されたクラスが求めるお作法(ボイラープレート)に従わせられる結果として、利用者側が苦労することになる。
クラス症候群の例
Java と Unix I/O
Javaでシリアライズされたオブジェクトを取得するためには下記のようなコードを書く
FileInputStream fileStream = new FileInputStream(fileName);
BufferedInputStream bufferedStream = new BufferedInputStream(fileStream);
ObjectInputStream objectStream = new ObjectInputStream(bufferedStream);
上の2つのオブジェクトは利用されない。最後の一行のインタフェースに求められているから、お作法として生成しなければならないだけ、っていうか、バッファされないInputStreamなんてそもそも無価値なのだから、そんなのデフォルトでいいし、ファイル開くために無意味な3行を書くのは苦痛、このようなインタフェースは病気。
インタフェースは、一般的なケースがデフォルトになるように作成すべきであって、全てのエッジケースに対応できるように作る必要はまったくない。効果的な複雑性の制御は、一般的なユースケースに最適化されたインタフェースによって達成される。
まとめ
モジュールをインタフェースと実装に分割することで、複雑さを隠すことができる。
利用者はインタフェースの抽象的な説明を理解することが利用できるようになり、全体的な複雑性が著しく現象する。
クラスをデザインするときは、深さに注意すること、一般的なユースケースに最適化して、シンプルなインターフェースをもつこと、これにより隠蔽された複雑性の量が最大化される。
Chapter 5 情報の隠蔽(と漏洩)
前章では深いモジュールの重要性について議論した。この章では、深いモジュールの作るテクニックについて議論する。
情報の隠蔽
最も重要なテクニックは情報の隠蔽。情報隠蔽については David Parnasによって初めて議論された。
基本的な考えとしては、簡潔なインターフェースをもち、重要な情報は実装に隠してしまう。つまり、外部のモジュールからは重要な情報は見えない。
例えば、こんな情報を隠蔽する
バイナリーツリーにどのように情報を保存するか、そしてどのようにアクセスするか。
論理ディスク内のファイルが物理ディスクブロックのどこにあるのかを特定する
TCPのネットワーク・プロトコルの実装方法
マルチコアプロセッサのスレッドスケジューリング
JSONをどうやってパースするか
隠蔽された情報は、データ構造やアルゴリズムを含む。
情報隠蔽は2つの方法で複雑さを軽減してくれる。
単純なインターフェース
モジュール利用者が事前に知るべき情報が少なくて済む
ソフトウエアの進展が楽になる
隠蔽された情報は、そのモジュールのみが依存関係を持つので、対処が楽
モジュールを設計するときは、どんな情報を隠蔽出来るか、慎重に考慮すること
情報を隠蔽すればするほど、モジュールは深くなり、インターフェースは単純になる
privateメンバー変数は情報隠蔽とは言えない。
アクセッサmethodがあれば内容の参照/編集ができるし。
良い情報隠蔽とは、不必要な情報がモジュール利用者に完全に見えない状態。
とはいえ、一部のコアな利用者のために一部の情報をあえて開示するような設計も、それはそれであり
情報漏洩
隠蔽の逆が漏洩
漏洩は、デザインの決定が複数のモジュールに反映された時に起こる。
そのデザイン決定に変更があれば、関係モジュール全部に影響する
インターフェースに情報が出てしまっている時、それを情報漏洩と定義する。
しかし、インターフェースに出てない情報でも漏れてるときがある
例えば、とある2つのモジュールが、それぞれとある共通のファイルフォーマットを扱うとする。
一方のモジュールは、それを使ってファイルの読み込みを、他方はファイルの出力するようなやつ
これらのモジュールはインターフェースでの情報漏洩はないが、共通のファイルフォーマットに依存する形で情報が内部から漏れている。 もしファイルフォーマットに変更があれば双方を修正しないとならない。
このような裏側からの情報漏えいはインタフェースからの情報漏えいよりもしばしば深刻。理由は漏洩の事実が分かりにくいから。
情報漏洩は、システムデザインにおけるもっとも気をつけなければならないレッドフラグの一つ。
自分が相対しているソースコードの情報が、そのクラス内、モジュール内で閉じていて、修正がそのクラス内・モジュール内で完結することを常に意識するべし。
もしも、既存のクラス間・モジュール間で情報漏洩がある場合は、まず隠れた漏れをインタフェースに持ってくるなどして明確化するアプローチもある。隠れているよりも表にだす、漏れているよりは隠す。
分割されすぎているモジュールやクラスを統合するアプローチもあり。
危険信号 : 情報漏洩。重要な情報が外に漏れている。漏らしすぎると利用者に不利益を与える。
時系列分解 temporal decomposition
とても一般的な情報漏洩のパターンを筆者は「時系列分解」と呼んでいる
システムのデザインが、運用で使われる時の時系列をそのまま表現しているパターン
例) 次のようなアプリケーションを考える
特定のフォーマットでファイルを読み込む
ファイルのコンテンツを編集する
ファイルを出力する
このようなアプリケーションを作ると、ソフトウェアの構造は3つのクラスに分けられる
1 ファイルを読み込むクラス
2 編集を行うクラス
3 ファイルを出力するクラス
1と3は特定のファイルフォーマットについての情報を共有しなければならないので、ここで情報漏えいが起きている
解決策としては、1と3をくっつけてファイル入出力クラスを作成すること。そうすれば情報漏えいがなくなる。
処理の順序というものは、どこかでアプリケーション内に記述される情報である。しかしながら、モジュールを設計するときは、順番を考慮にいれてはいけない。あくまでどの情報を隠蔽し、何をインターフェースに露出させるかに集中すること。
危険信号 : 時系列分解。システムデザインは時系列と切り離して考えること。
HTTPサーバー
ここから先は、学生に作成させたHTTPサーバの実装例でよく見られるコードを例にとって、情報漏洩について説明する。
下はウェブサーバが受け取るリクエストの例。
2019-01-25 10_15 Office Lens.jpeg (141.3 kB)
多すぎるクラス
まず一番よく見られるのが浅いクラス・モジュールに分割させすぎる例
「時系列分解」が行われた結果、リクエストの文字列の解釈が以下のようなクラスに分けて作成される
ソケット通信をしてリクエストを文字列に読み込むクラス
文字列をHTTPのリクエストの各項目にパースするクラス
このアプローチは一見正しそうに見えるがNG。HTTPリクエストはContent-Lengthを持っている。そのため1のクラスが正常に動作するためにはリクエストが2でパースされている必要がある。つまり1と2は共通の情報を必要としているのに時系列で分けたために情報漏洩が発生している。こいつらは本来ガッチャンコされないといけない。
さらにこのクラスを利用するひとは、HTTPリクエストを読み込むために、複数のクラスの異なるメソッドを時系列にそって呼び出さなければならない。これはモジュール利用者側にとっても繊細な知識が要求されるので厳しい
この例が示すように、この本が推奨する深いモジュール・情報隠蔽は、クラスやモジュールを少し大きくすることで、改善される
そういうことを言うと、全部を1クラスに押し込めるような強者が現れるが、その話は9章でKWSK
HTTPパラメータのハンドリング
リクエストをパースしたあと、リクエストパラメーター取得のメソッドを学生が書くのだが、よくある駄目なパターンが下記
public Map getParams() {
return this.params;
}
このメソッドは浅い。このメソッドは内部実装を外部に露出してる。つまり内部ではリクエストパラメーターを文字列のMapで格納しているという情報が外に漏れてる。
改善されたインターフェースは下記
public String getParameter(String name){ … }
public int getIntParameter(String name){ …}
これによって、モジュール利用者は、自分たちの手元でparseIntする必要がなくなる。戻り値が文字列なのか数値なのかをいちいち気にする必要もなくなる。拡張も楽
public double getDoubleParameter(String name){…}
デフォルトレスポンス
HTTPサーバーの実装ではリクエストのハンドリングの後にレスポンスの出力がある。学生がやりがちなミスとしてレスポンスの全ての設定値を利用者にセットさせようとするものがある。
例えばレスポンスにはHTTPのバージョンや、メソッドを設定するが、それらはリクエストの値と一致する必要があるんだから、デフォルトでセットしておけばいいよね??そうすることで利用者は、本当に利用者のみが作成する必要があるレスポンスに集中できる。
たまに、デフォルト値以外の値を返したい変速パターンがあるかもしれないが、それはそのための特殊なアクセッサメソッドを容易しておけば良いだけ。
危険信号 : 露出しすぎ問題。インタフェースにアクセッサを作りすぎて、利用者に過度の負担を求めている
クラス内・モジュール内での情報隠蔽
クラス外部へのインタフェースだけでなく、クラス内・モジュール内でも情報隠蔽のアイデアは使える。
例えば、アクセス修飾子を使うとか。final使うとか
隠しすぎ
情報隠蔽で気をつけることは、隠しすぎてしまうこと。利用者が知るべき情報は露出していなければならない。隠しすぎると、そもそも利用できない使いづらいインターフェースになる。
まとめ
情報隠蔽は深いモジュールに繋がっていく、そして深いモジュールはたくさんの情報を隠蔽しているがゆえに高い機能性をもつ。
これを逆に捉えると、情報が隠れていない浅いモジュールは大した機能を提供していないということになる。
実行時の順番に囚われて設計を行うとろくな結果にならない。情報漏洩と浅いモジュールを作り出してしまう。
そうではなく、モジュールが行うタスクとそのために必要な情報、そしてどの情報を隠蔽できるかにフォーカスすることで良いモジュールを作ることが出来る。
Chapter 6 一般用途向けモジュールはより深く
システムデザインのとても一般的な決断
- 一般用途のモジュール
- 専門用途のモジュール
よく言われるのは、より広い問題解決に使えるように一般用途を考えて作れという意見
三章で学んだ通り、少しの時間を追加投資して、より使いやすいよいモジュールを作るのは、経済合理性がある。
他方で未来予測は難しい yagni
より幅広い用途を意識したが故に、今抱えている問題点に対して、あまり役に立たないという本末転倒もある。
結果として現在のアジャイルなアプローチの場合、まずは専門用途で作成して、将来的に他の用途が見つかった時点で、リファクタリングして、より一般化するというのが筋が通っているようにみえる。
ほんのり一般化
筆者の意見では、ほんのり一般化するのが良い落とし所。
ほんのり一般化とは? 原著 somewhat general purpose
つまり、機能は専門的で良いが、インターフェースまで専門的にしない。インタフェースは一般用途でも使える形にして将来に備えて、実装はバリバリ専門的にする。
インタフェースまで専門的にしてしまうと将来性がない。仮に他の使い道が出た時に身動きが取れない。なので、ほんのり一般化しておくのが良い。
例: テキストエディタの開発
生徒達が作ったエディタは専門的な用途のAPIを備えていた、生徒たちはこのAPIがテキストエディタで使われることを知っていた。
例えば、BSやDLキーの挙動。
void backspace(Cursor cursor);
void delete(Cursor cursor);
例えば、選択領域の削除
void deleteSelection(Selection selection);
こうして、Textクラスに専用の関数を配備していった結果として、Textクラスは一つの用途しか持たない浅いメソッドであふれかえるようになった。例えば、deleteメソッドはdeleteキーを押されたときしか使われない。
一見良さそうなアプローチだが、情報漏えいが発生している。ユーザインタフェースの細かい仕様に合わせてAPIを容易したことで、
Textクラスは、ユーザインターフェースと密結合になってしまった。
つまり、ユーザインターフェースのささいな変更が、Textクラスの実装に影響を与えてしまう。
専門用途のモジュール開発は、おうおうにして密結合なクラス間関係を導き出す。
より一般用途を意識したアプローチ
広い用途のinsert, deleteメソッドに合わせて、Cursorの位置を制御する関数を用意することでAPIはより汎用的になる。
void insert(Position position, String text);
void delete(Position start, Position end);
Position changePosition(Position position, int numChars);
このAPIを使うと、テキストの削除はこう書ける。
text.delete(cursor, changePosition(cursor, 1)); //deleteキー
text.delete(changePosition(cursor, -1), cursor); //bsキー
これは専用用途アプローチで作られたAPIより冗長だが、このAPIは汎用性があるため、複数用途で使い回すことが出来る。
APIが良い抽象化を達成している。
一般性は良いシステムデザインに繋がる。
上の例は、汎用性のあるAPIを作るアプローチが以下のことを達成していたことを示唆している。
「Textクラスはユーザインタフェースクラスの詳細を知る必要がない」
また、APIが汎用的になることで、APIを利用する側もリファレンスを探すのが楽になる。良いことだらけ。
気をつけるのは、誰が何を、いつ、知る必要があるか?を念頭に置くこと。
良いシステム設計のための問い
自分自身に問うべきだ。
- 今の自分の要望をすべて満たすことができる、もっとも汎用的なAPIインターフェースはなんだろうか?
- 一体どれくらいの状況でこのAPIは使い回されるだろうか?
- このAPIは、現在の自分の要望に対して、使いやすいだろうか?
これらの問いを投げかけることで、良いシステムデザインを達成することが出来るだろう。
まとめ
良いシステムデザインを作るベストの方法の一つは、あなたのクラスが持つAPIをほんのり汎用化してあげることで達成することができる。
Chapter 7 異なるレイヤー、異なる抽象化
ソフトウェアシステムは層で構築されている。より上位層は、下位層が用意してくれたモノを使う。
よくデザインされたシステムでは、それぞれの層は異なる抽象化を提供する。
例
- ファイルシステム => 最上位層は抽象ファイル、一つ下の層はブロックデバイスから読み取ったデータをキャッシュした内容をやりとり、最下位はデバイスドライバー等で構成され、物理ドライブからデータを読み出す
- TCPプロトコル => 最上位層はデータのストリーム、下位層はパケットを受け渡して、転送制御を行っている。
Red Flag もし、隣り合う層が、同じような抽象化を提供している場合、それは良くないシステム設計の匂い、クラス構造の崩壊を示唆している。
この章では、どこでそのようなことが起きているのか?そして、どのように対処したら良いのかを語る。
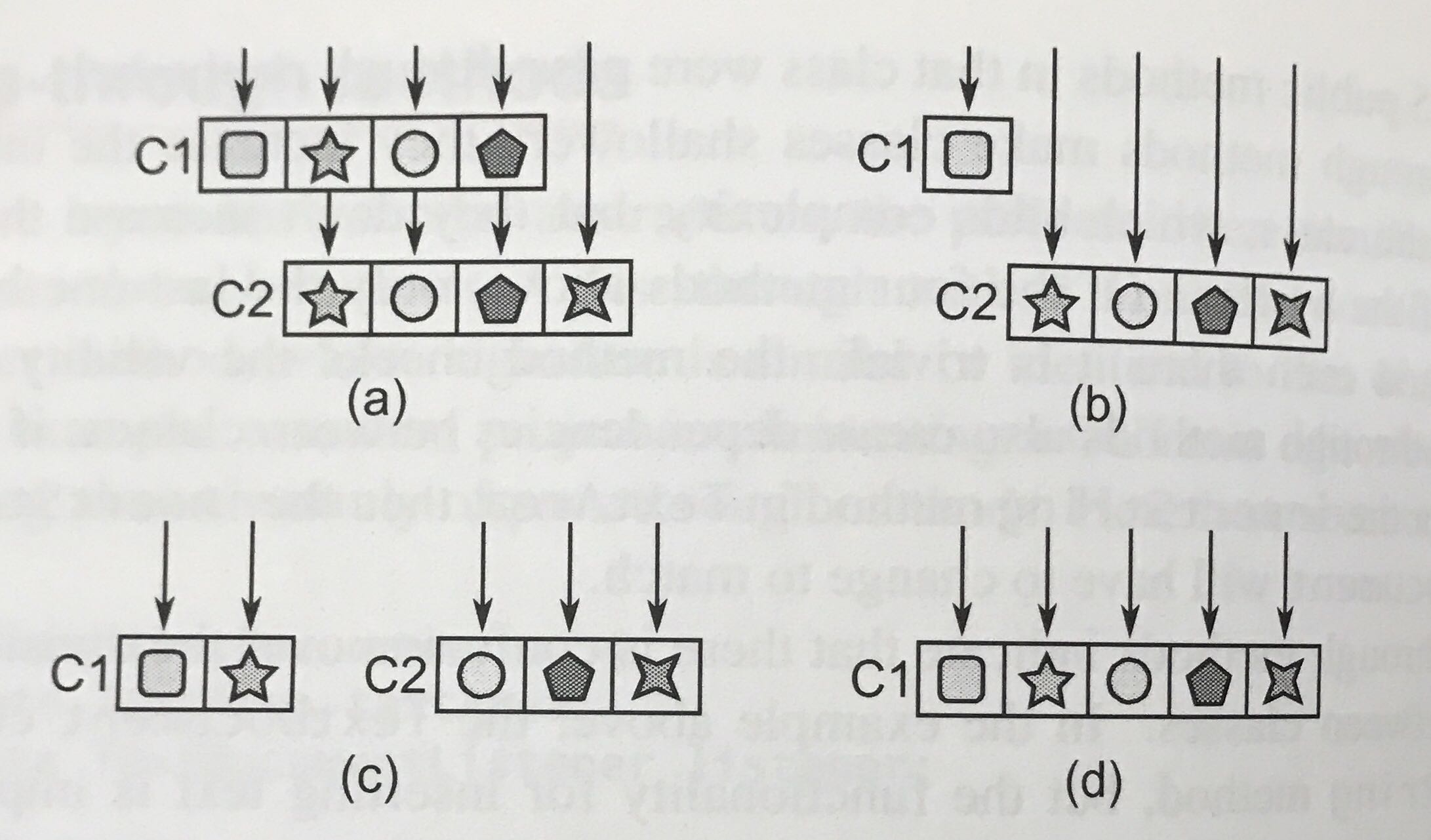
7-1 引数素通しメソッド
もし、クラスAのメソッドが、クラスBの同じ引数のメソッドを呼び出すだけの役割をしていたら、それは
「クラスAとクラスBの責務が適切に分割されていない」ことを示唆している。
サンプルコード
public class TextDocument {
private TextArea textArea;
public Character getLastTypedCharacter(){
return textArea.getLastTypedCharacter();
}
}
このような場合、クラスAクラスBの責務を考え直す必要がある。対処方は、クラスAとクラスBがそれぞれ区別された、適切な責任を持つこと。
下図(a)は、クラス分割が不明確な場合、(b)は単純にそれぞれ固有のメソッドのみ残した場合
(c)は、それぞれの責務に合わせてメソッドを再配置、(d)役割に違いが無いのであればクラスをマージしてしまう。
7-2 インターフェースの重複はOK?
interfaceが重複していることは、常に悪いことではない。例えばdispatcher WAFのRoutingとかはまさにコレ。
その他の例としては、DIパターンやFactoryパターンなどで使われるInterface.
それぞれ異なる実装を行うために同じ引数とメソッドを持つ実装クラスが存在しているパターン。これも問題なし。
7-3 デコレーターパターン
これは、デザインパターンではよく行われる。Wrapperパターンなどとも呼ばれる。
Java IOパッケージでは、InputStreamにBufferingの機能を追加 BufferedInputStreamが提供されている。
Decorator Patternは、元のソースコードに対して、ちょっとした機能追加や利便性の提供を行う動機で作られることが多いが、ちょっとしたなので、クラスが浅くなりがち。
結果として、Java IOのように同じインタフェースを持つ多種類のクラスを持つことになり、実装者が戸惑ってしまう。(InputStreamとか使わないじゃんね。と)
Decoratorが理にかなっていると思われるときもあるが、大概はよりよい代替案がある。
無闇に重複したInterfaceを持つクラスを量産するのではなく、一度立ち止まって思いとどまるべし。
7-4 インタフェース VS 実装
クラスのInterfaceは、通常はその実装と異なるべきというルール。つまり、Interfaceで示唆されている抽象化と、実装で行われている抽象化が同程度であれば、そのInterfaceは、複雑さを軽減できていないということ。
テキストエディタ作成の授業において、80%くらいの生徒は
getLine
putLine
という行指向のAPIを用意した。このAPIは、その実装とまったく同じ抽象化がなされていて、行単位での編集作業を行う。しかし、実際の世界では文中で文字を入力することもあるので、行単位で処理をするのは不十分
行指向APIを用意した生徒は、文中で改行コードを入れ込むような編集作業を行う場合は、getLineした後、中身を複数行にして、putLineをループで出力するような複雑な行為を行う必要があり、実装も不必要に辛くなった。
これは抽象化が、複雑な実装を抱え込むことが出来ないことが原因で、解決策の一つとしては
insert
というAPIを用意して、それは行単位だろうが、文字単位だろうが、テキストエディタへの挿入を行えるという深い抽象化を行うべき。
※この内容は5章、6章の話とすこし重複していると思う。
7-5 素通し変数
とりあえず、何もいわずに図の左上を見てほしい。Pass-Through Variablesは最奥で変数を利用する関数のために、その中間にいる関数が、変数を持ち回している現象をさす。
中間にいる関数は、その変数をまったく弄くらないこともある。

対処方法
(b) すでに引数を最初に受け取る箇所と、最後に受け取る箇所の間にShared Objectがある場合は、それを利用する。
(c) global変数を使う。global変数の功罪は分かるが、pass-throughされるよりはマシ
(d) 筆者お勧めは、Contextオブジェクトを用意し、各クラスがContextオブジェクトを取得できるメソッドをpublicに用意すること。
Contextオブジェクトは解決策としてはエレガントなのだが、以下の懸念がある。
- なんでもかんでもContextに詰めだす、とりあえずContextに詰めとけ症候群を生む。
- Contextの値の存在によって、明確でない依存関係が生まれる可能性がある。
- ContextはGlobal変数の欠点をそのまま多く受け継いでいることを忘れないように。
- Contextオブジェクトの変数内容を途中で変更される -> immutableで防ぐ
筆者は、Contextオブジェクトは理想からはほど遠いとしているが、ルールをもっと適切に運用することを条件として、コレ以外にマシな解決策は今の所無いと言っている。
7-6 まとめ
Different Layter, Different Abstraction
このデザイン思想は、Pass-Throughが行われている箇所で、抽象化や役割分担が明確でないことを意識するためのもの。
Pass-Throughを見かけたら、なんかクラス構造がイケてないのでは?と考える契機になる。

コメント